

人工知能の入門書はないか・・・最近、そんな資料を求める人が多くなった。このところ、テレビやネットで「人工知能」や「AI」のキーワードを頻繁に目にする。いまやあらゆる業界、立場の人にとって、知らないでは済まされなくなってきた。
入門書が見つからない
皆が知りたいのは、「人工知能って何?」そんな素朴な疑問にズバリ回答した資料だ。
ところが、いくら探してもこの手の入門書は見つからない。「入門」と名の付く本はあるが、専門家が書いたものが多いため、漠然とした動向か、専門用語が並んだ難しい内容の本が多いようだ。
一応、人工知能の入門書
人工知能(AI)とは何か
人工知能についてWikiを調べると、次のように書かれている(ちょっとだけ変えてあります)。
“人工的にコンピュータ上などで人間と同様の知能を実現させようという試み、
或いはそのための一連の基礎技術のこと”
人工知能は既に身近にある。iPhoneの Siri や、Windowsの Cortana 。アマゾンで買い物をしていると「おすすめの商品」とかいって出るやつもそう。
テレビやネットの報道を見ると、人工知能はもっと広い意味で使われている。少しでもそれっぽいものは、何でも都合よく「人工知能」と称してPRされているようだ。
IoTやって何するの?
IoTとはモノをネットにつなげて何かする、というもの。製造業を営む企業ではどこもIoTに力を入れている。大抵は上からの命令だ。
実はこれ、人工知能と深い関係があるのだが、
センサーつけてデータ集めて・・それで何するのか??
やらされている側は、何をするためにセンサーを追加するのかがよくわからない。
多く企業でデータを集めたあとのビジョンがない。普通はビジョンや目的が先にあって、そのためにセンサーを付けるなどのアクションをするもの。
「何のためにやるんですか?」上に聞いてもマシな答えは期待できない。しかし、目的もなく取ったデータでも、沢山集まれば、後述するようにいろいろ役に立つ。いまはただ、黙ってデータを集めることが重要だ。
機械学習って何?
通常、人工知能は、「機械学習」して作られる。
機械学習については SAS Institute Japan の次の説明がわかりやすい
「データから反復的に学習し、そこに潜むパターンを見つけ出すこと」
要するに、人工知能とは、データを使って学習させた演算機(アプリ)のこと。
といっても、まだ少しってもピンとこないかもしれない。機械学習の具体的手順は、エクセルのcsvファイルか、画像データ(写真)などを用意して機械学習するソフトに読み込ませて計算するだけ。
機械学習の中身がどうなっているのか、気になる人がいるかもしれない。それはテレビがどうして映るのか、知らなくても生活に支障がないのと同じ。理屈を知る必要はない。
人工知能で何ができるの?
物体の特徴を自分で覚えて、人間の代わりに判断できるアプリを作れる。
これを実現するためには、人間が物事を覚えるのと同じように、データが必要だ。次の例がある。
クルマの自動運転をやるために、信号、標識、クルマなどを識別したい
→信号、標識、クルマの画像データを使って学習させる。
食品の異物検知をしたい
→異物の無い画像、異物の入った画像のデータを使って学習させる。
東方キャラの顔から名前を識別したい
→キャラ別の画像と名前をセットにしたデータを使って学習させる※。
異性の好感度を数値化したい
→顔写真と好感度をアンケート調査して集めたデータセットを使って学習させる。
ワインのパーカーポイントを機械で計算させたい
→パーカーポイントが付いているワインを味覚センサーで測定し、そのデータセットを使って学習させる。
顔でも、言葉でも、芸術の感性でも、関西人の度合いでも、何でも、どんなことでも、データさえあれば、覚えこませて人間の代わりに判断するアプリを作れる。
※:分類問題のアプトプットは確率。霊夢98%、咲夜1%・・だからこれは霊夢なんだといった感じになる。
ただし、人工知能に教えるのはあくまで「人間」。人間が「あれは信号だよ」「あれはクルマだよ」というように教えなければならない。人間が教えたものについては、人間並みか、それ以上の精度で識別できる(ミスをしないので)。
人間が教えるので、人間が識別できるものは、基本的に学習させることが可能。今の人工知能は自分で自分を改良する能力がないので、人間の認識範囲を超える識別はできない。
10年後に今の半分の職業が消えてなくなるって本当?
「これ印刷ですね」
掛け軸の目利きも、本物と印刷の掛け軸(無数の画像データ)を人間が見て、違いの特徴を獲得した結果だ。
掛け軸に限らず先の事例は、どれも今まで人間にしか出来ないとされていたこと。これが出来るとなれば、今後はどんどん、機械に代替されていくだろう。
経験や知識を元に成り立っている商売は、今後どんどん無くなっていく。これはもう止めようのない流れだ。
ディープラーニングって何?
人間は、「これは飛行機だ」「クルマだ」というように判断できる。人間の脳は、これらを写真のような画像で記憶しているわけではなく、これらの「特徴」を憶えて判断しているといわれている。例えば「翼、胴体、尾翼」といったものが認められれば、「飛行機」と判断するようにだ。
人工知能も人と同じように、沢山のデータから共通する特徴を見つけ出して記憶する。
これによって、
物体の特徴を自分で覚えて、人間の代わりに判断できるアプリを作れる。なぜそんなことが出来るのか!? ここで「ディープラーニング」が登場する。
ディープラーニングとは、深層学習、つまり多段結合されたニューラルネットワーク※を学習するための学習方法だ。
※:ニューラルネットワーク:人の脳神経細胞を模擬した単純な演算機(ニューロン)を沢山繋げた回路網のことやねん
ニューラルネットワークをたくさん繋いで深くすれば、データから特徴を自分で見つけ出せる人工知能ができるかもしれない・・この可能性はかなり前から予測されていたが、計算機の能力がボトルネックになってなかなか研究が進まなかった。
ゲーム用のグラボが人工知能の学習を加速させる
人工知能の発達とゲームの発達は無関係ではない。
ディープラーニングの計算には膨大な演算を必要とする。実はこの計算が、ゲームでリアルなグラフィックを作るための計算と共通していた。
NVIDIAのグラボには「CUDAコア数」というスペックがある。これがニューラルネットの学習計算に役立つ演算能力を示している。
NVIDIAは早くからこれに目を付けて、ゲームとは別に、自社のグラボを活用したディープラーニングのビジネスを拡大している。
 NVIDIAではDIGITSというフリーソフトを配布している。これをインストールすれば、クリックだけで簡単にディープラーニングを実行できる※。それはワードやエクセルを使いこなすより、はるかに簡単だ。
NVIDIAではDIGITSというフリーソフトを配布している。これをインストールすれば、クリックだけで簡単にディープラーニングを実行できる※。それはワードやエクセルを使いこなすより、はるかに簡単だ。
※:ディープラーニングの実行に必要なハードは普通のPCでOK。お金も、ほとんどかからない。グラボは必須ではないが、ないと計算時間が数十倍に増える。
<関連商品>
グラフィックボード(ビデオカードともいう)はディープラーニングの計算にも使われます
Jeston ラズベリーパイ感覚で人工知能を実装できるNVIDIAの組み込みボード。机のPCだけでなく、産業機器や生産ラインで人工知能を活用できます
人工知能の中身はどうなっているのか
「人工知能の中身が見たい」と思う人がいるかもしれない。人工知能の中身を覗いても、抵抗やコンデンサ、歯車などは見えない。
多段結合されたニューラルネットの実態は、大規模な行列演算機(ソフトウェアのプログラム)だ。学習で獲得するという「特徴」の実態は、その個々の係数(ニューロンの重み係数)にすぎない。
「コレでどうしてスタイルやメイクから男性の好感度が計算できるの?※」
そう考えて係数を眺めてもサッパリわからない。これは人間の脳を覗いてもわらないのと同じ。「中身が見えるブラックボックス」といえる。
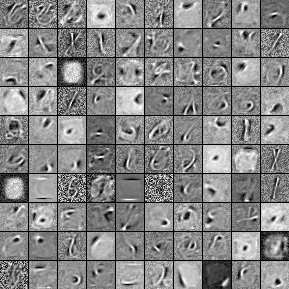
出典:deeplearning.net/tutorial/
ちなみに、数字などの単純な画像の特徴を学習させたものは、どんな特徴を覚えたのかイメージできる形に視覚化できる。
左はMNIST(0~9までの手書き数字データセット)をディープラーニングして覚え込ませた結果。画像では人工知能が具体的に数字のどんな特徴を獲得したか、視覚的に観察することが出来る。
※:顔のメイクから男性の好感度を数値化するAIは、メイクの写真と、それに対する好感度を調査したデータがあれば実現可能だ。
データがなければ何も始まらん
多段結合されたニューラルネットとディープラーニングがいくら優れているといっても、学習させなければ何の役にも立たない。
そのために必要なのが「データ」だ。しかもできるだけ多いほど良い。ここで、IoTやビッグデータの話と繋がってくる。
IoTやって何するの?
その目的は工知能を作るためのデータを集めることだ。モノをネットにつなぎ、クラウドにデータを蓄積する。これを続けていくと膨大なデータが集まる(ビッグデータ)。
沢山のデータがあれば、いろんな切り口で人工知能の学習に活用できる。これによって、今までにない、新しい商品やサービスが創造できる。自動運転もその一例だ。
これからのビジネスは「データをどれだけ持っているか」で決まる。会社の大小や、広い工場、生産設備の優劣はもう関係ない。数人のベンチャーが特定分野でgoogleに勝つことだって不可能ではない。
データを熱心に集める企業と、集めない企業とでは、将来、どうしようもない格差が生まれると、私は予測する。
無料クラウドサービスの落とし穴
ところで、人工知能で先行するGoogleはずいぶん前から熱心にデータを集めている。Googleにとって、のどから手が出るほど欲しいものがある。それは、個人が作った写真、文書、音声のデータだ。
例えば写真のようなものは、「あなたが撮った写真、くれませんか?」と言って貰えるものではない。お金を積んでもダメ。そこで、
「写真の置き場に困っていませんか?うちで作りましたので自由に使ってください。もちろん無料です」
としたのだ。こういったサービスを展開する企業はほかにもある。規約を読むと、大抵は置き場を提供した人がサービス向上を目的(人工知能の学習に)に自由に使っていいことになっている。
将来、機械に支配されるかもしない
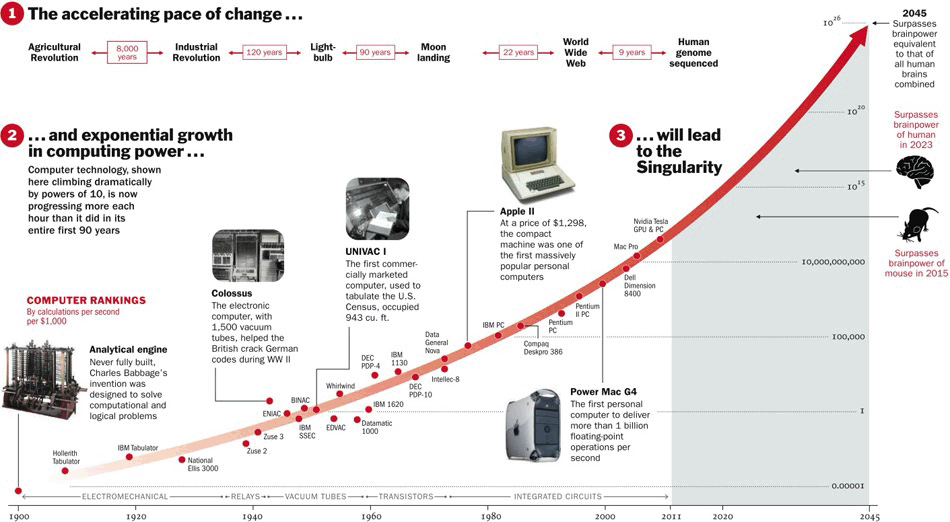
コンピューターの進歩と今後を予見するロードマップ (http://content.time.com/time/interactive/0,31813,2048601,00.html)
ムーアの法則という言葉がある。コンピューターはこれに従って進歩してきた。それが終わるのが2045年。ここでコンピューターは、自分で自分を改良する能力を身に付け、加速度的な進化を始めるという。
この変化点のことを「シンギュラリティ」といわれている。
シンギュラリティの先に何が待っているのか、私たちにはわからない。いま、人工知能を作る関係者の間で、懸念されている問題の一つだ。私は次のような結末を想像している。
人間は働かなくてよくなり、南国のビーチでトロピカルジュース片手に日光浴できる。
環境を汚し資源を食いつぶすだけの人類は必要ない・・そう思われて抹殺される。
ロボットが地球を支配し、人類は愛玩用のペットとして生かされる。
・
・
心配だからシンギュラリティの手前で進歩を止めたい
そう思う人もいるが、私たちにはどうすることもできない。おそらく、この分野で一番進んでいるGoogleがやらかしてしまうだろう。
2045年といえば、もうすぐ。この記事を読んでるほとんどの人が生きている。みんなでその結末を見届けようではないか。
<参考購入先>
深層学習 定番の本です
<関連記事>
Pepper と無料クラウドサービスの罠
Google Glass失敗!~Googleが進める自動運転の本当の目的は・・
【2020最新版】ディープラーニング用PCを安く作る方法
<参考文献>
ディープラーニング 情報処理学会研究報告 Vol.2013-CVIM-185 No.19
技術解説 ディープラーニング 映像情報メディア学会誌 Vol.68,No.6,p466-471